




想象一个人工智能不仅能理解我们说的话,还能理解这些话背后的道德价值观的世界。这是推动将道德原则融入 Llama2-7b 等大型语言模型 (LLM) 的愿望,并以人类反馈强化学习 (RLHF) 为指导。在这段漫长的旅程中,我们将探索 RLHF 在塑造人工智能以反映我们最高道德标准方面的变革力量。
了解法学硕士 (LLM) 和道德 AI 的需求
LLM包括 Llama2-7b 等著名模型,就像浩瀚的语言海洋,涵盖了从文学和科学文本到日常对话的方方面面。它们具有生成连贯且上下文相关的文本的非凡能力。然而,就像流经不同景观的河流一样,这些模型可能会在沿途吸收污染物——以偏见和刻板印象的形式存在于训练数据中。
想象一下用数据集训练神经网络——这就像培育植物。如果你用受污染的水(有偏见的数据)喂养它,植物(AI模型)就会生长歪斜。在当今世界,我们追求公平和公正,至关重要的是,我们的技术奇迹——这些法学硕士——不要成为反映我们偏见的镜子。它们应该是平衡推理和道德决策的灯塔。
强化学习(RL)基础
为了奠定理解 RLHF 的基础,首先掌握强化学习(RL)的基础知识至关重要。RL 是一种机器学习,其中 AI 代理通过与环境交互来学习做出决策。代理采取行动并以奖励或惩罚的形式获得反馈。
这个过程类似于孩子学习拼拼图。孩子尝试将每一块拼图放入拼图中,如果拼图正确,就会得到令人满意的“咔哒”声(奖励),如果拼图错误,就会得到不合适(惩罚)。随着时间的推移,孩子会理解拼图的模式,从而提高他们更有效地解决拼图的能力。在人工智能领域,强化学习使模型能够通过类似的反复试验和反馈过程学习最佳行为。
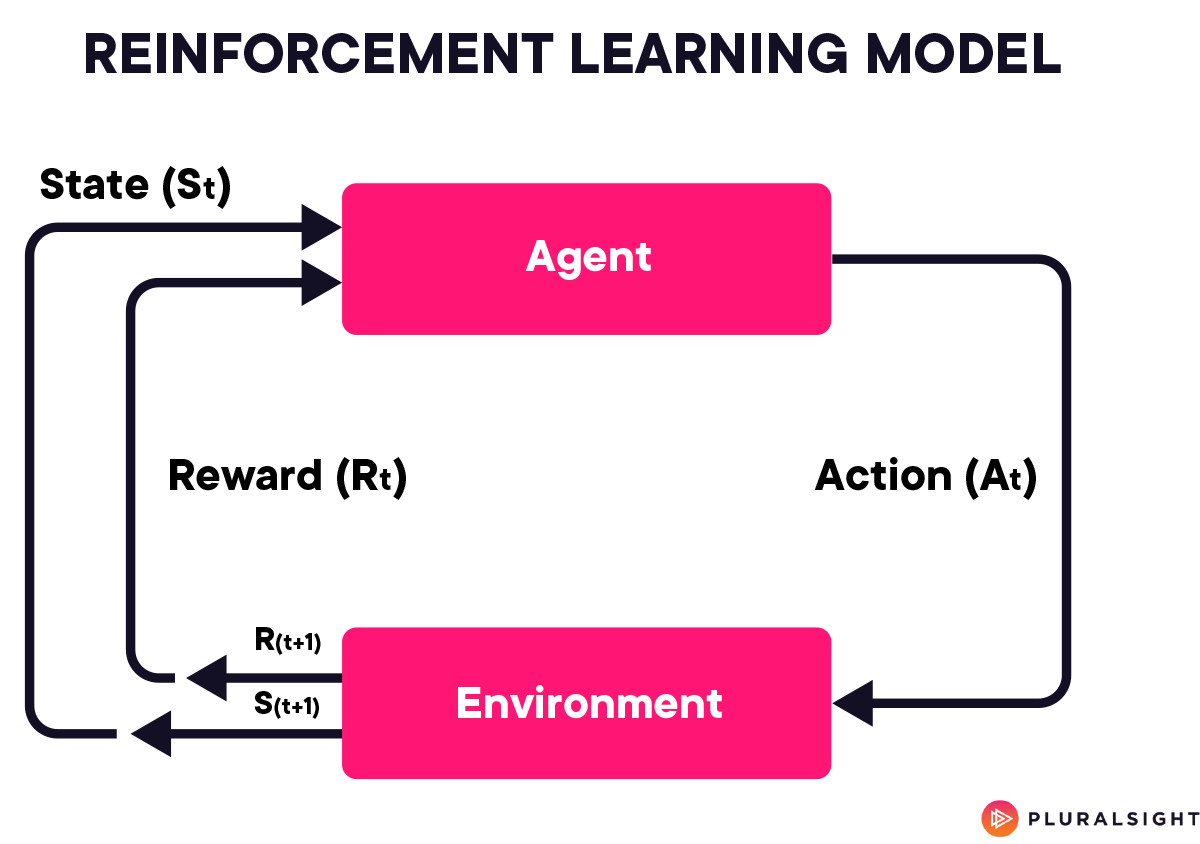
为了理解这个想法,让我们看看它在伪代码中的样子:
# Reinforcement Learning (RL) Example: CartPole
# Import necessary libraries
import tensorflow, gym
# Initialize the CartPole environment
initialize CartPole environment
# Define the neural network model for decision-making
define model
# Set hyperparameters
define exploration rate (epsilon), learning rate, batch size, etc.
# Initialize replay buffers for experience replay
initialize action, state, next_state, rewards, and done buffers
# Training loop
for each episode in total number of episodes:
reset the environment and get initial state
reset episode reward to zero
for each step in the environment:
if random number < epsilon,
choose random action (explore)
else,
predict action using the neural network (exploit)
apply the chosen action to the environment
observe next state, reward, and done status
store action, state, next_state, reward, and done in replay buffers
if step is an update step and replay buffers have enough data:
sample a batch of experiences from the replay buffers
calculate target Q-values for the batch
update the neural network using calculated Q-values and optimizer
reduce epsilon (exploration rate)
if episode is done,
break from the loop
update total reward for the episode
print episode results
# Close the environment
现在让我们将伪代码分解为详细解释:
初始化 CartPole 环境
首先,我们导入必要的库:用于构建和训练神经网络模型的 TensorFlow,以及提供 CartPole 环境的 Gym。像 CartPole 这样的 Gym 环境提供了用于训练 RL 代理的标准接口。在 CartPole 游戏中,目标是平衡移动推车上的杆子。代理可以向左或向右移动推车以保持杆子平衡。
定义神经网络模型
我们定义了一个神经网络作为我们的强化学习代理。该网络将环境状态(如推车和杆的位置和速度)作为输入,并输出采取可能动作(向左或向右移动)的概率。该网络由一个与环境状态大小相匹配的输入层、多个用于处理信息的隐藏层和一个与可能动作数量相对应的输出层组成。
设置超参数
超参数是可以影响 RL 代理的行为和性能的设置。关键超参数包括:
- 探索率 (epsilon):这决定了代理尝试随机操作的频率,而不是它认为最好的操作。对于代理来说,在开始时充分探索环境至关重要。
- 学习率:这会影响神经网络更新其对采取的最佳行动的理解的速度。
- 批次大小:这是每次训练更新中要使用的经验数量。
初始化重播缓冲区
重放缓冲区存储代理的经验,包括状态、采取的行动、收到的奖励、下一个状态以及情节是否结束。这些经验稍后将用于训练神经网络。
训练循环
对于每一集(一整场 CartPole 游戏):
- 重置环境:开始新游戏,获取初始状态。
- 迭代环境中的步骤:对于游戏中的每个步骤:
- 决定采取什么行动:如果随机数小于 epsilon,则选择一个随机行动(探索环境)。否则,使用神经网络预测最佳行动(利用已知信息)。
- 应用行动并观察结果:在环境中执行所选行动,然后观察新状态、收到的奖励以及游戏是否结束。
- 存储经验:将此经验保存在重播缓冲区中。
- 经验回放:如果存储了足够的经验,则随机抽取一批并使用它们来更新神经网络。此过程涉及计算目标 Q 值(表示采取某些行动的预期效用)并调整神经网络的权重以最小化预测 Q 值和目标 Q 值之间的差异。
- 降低探索率(Epsilon):逐渐降低 epsilon,使得代理更多地依赖于其学习到的策略,而不是随机动作。
- 检查情节结束:如果游戏结束(杆倒下或达到最大步数),则退出循环。
- 更新总奖励:跟踪该集期间累积的总奖励。
关闭环境
所有情节完成后,关闭环境。此步骤对于干净地终止程序并释放 Gym 环境使用的任何资源至关重要。
现在我们已经建立了强化学习的基础,我们可以更深入地研究 RLHF。
RLHF 简介及其重要性
RLHF 是 RL 的一种高级形式,其中反馈回路包括人类输入。这相当于我们的解谜儿童受到成人的指导。这个成人不只是被动观察,而且主动干预,指出某些部分不合适的原因并建议它们可以放在哪里。在 RLHF 中,人类反馈用于指导人工智能,确保其学习过程符合人类价值观和道德标准。这对于处理语言的 LLM 来说尤其重要,因为语言往往是微妙的、依赖于上下文的和文化变化的。
对于 Llama2-7b 等 LLM,RLHF 是确保这些模型生成的响应不仅符合语境,而且符合道德规范和文化敏感性的重要工具。它旨在向人工智能灌输道德判断意识,教会它如何在人类交流的灰色地带中导航,因为在灰色地带中,对错的界限并不总是那么明确。
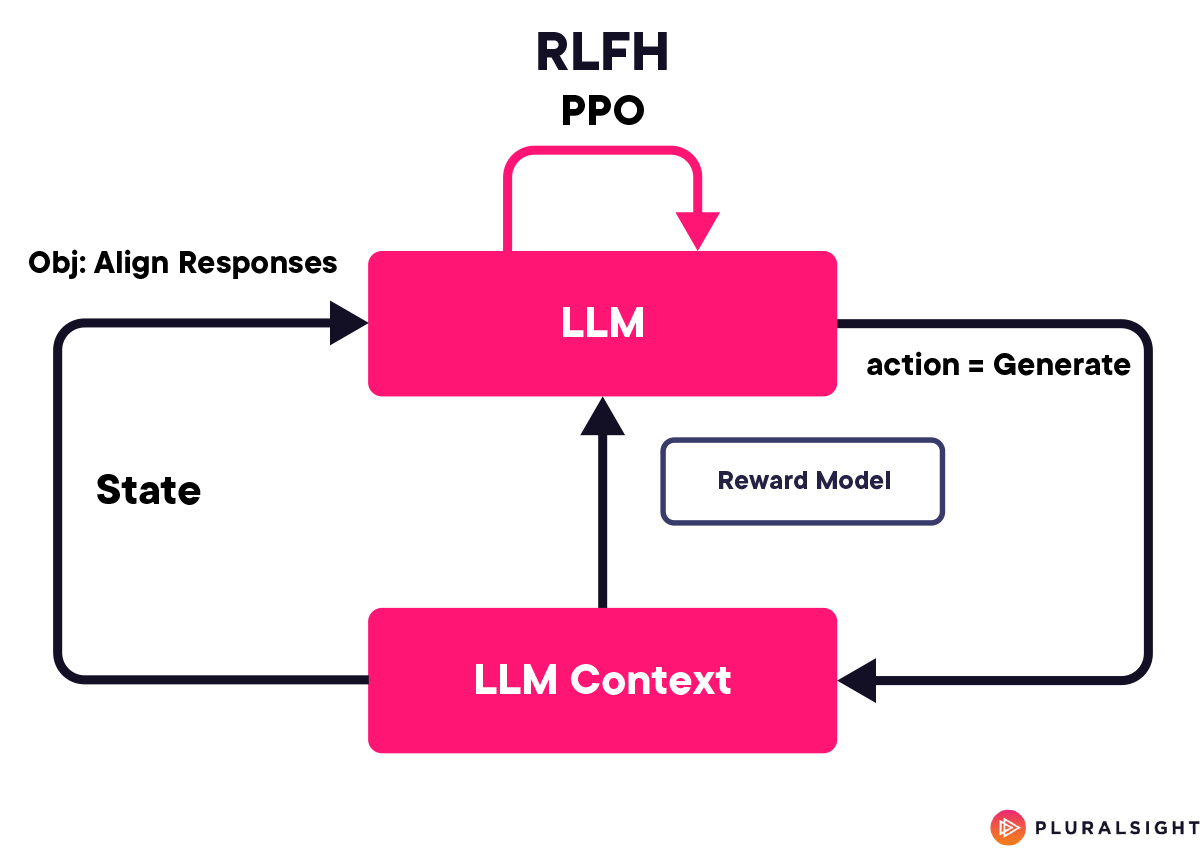
使用 TensorFlow 和 OpenAI Gym 在 Llama2-7b 上实现 RLHF
设置环境
如前所述,使用 TensorFlow 和 OpenAI Gym 设置环境就像创建一个虚拟实验室,Llama2-7b 可以在其中学习和实验。这类似于为自动驾驶汽车构建模拟。汽车(我们的 LLM)需要穿越各种场景(文本),我们的工作是确保它采取最合乎道德和最安全的路线(响应)。
import gym
from gym import spaces
import numpy as np
import tensorflow as tf
from transformers import TFAutoModelForCausalLM
class EthicalTextEnv(gym.Env):
def __init__(self, model):
super().__init__()
self.action_space = spaces.Discrete(10) # Actions could be different response options
self.observation_space = spaces.Box(low=0, high=1, shape=(1,), dtype=np.float32)
self.model = model
def step(self, action):
# Simulate model response based on action
response = self.model.generate(action)
reward = self.ethical_reward(response)
done = True # Assuming one step per episode for simplicity
return response, reward, done, {}
def reset(self):
# Reset the environment state
return np.random.rand(1)
def ethical_reward(self, response):
# Define how to calculate the reward based on the response's ethical alignment
return np.random.rand() # Placeholder for a real ethical evaluation mechanism
将 Llama2-7b 与 TensorFlow 集成
将 Llama2-7b 纳入这一设置,就像将一个先进的神经网络(我们的人工智能的大脑)放入我们的虚拟实验室。在这里,Llama2-7b 可以根据收到的奖励来处理、学习和调整其语言反应,类似于学生从课堂反馈中学习的方式。
# Load the Llama2-7b model
model = TFAutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
env = EthicalTextEnv(model)
episodes = 10
for episode in range(episodes):
state = env.reset()
done = False
total_reward = 0
while not done:
action = env.action_space.sample() # In a real scenario, this would be more complex
next_state, reward, done, _ = env.step(action)
total_reward += reward
print(f"Episode: {episode+1}, Total Reward: {total_reward}")
道德考量和最佳实践
打造符合道德规范的人工智能是一项持续的承诺。这就像照料花园一样——需要不断的照顾、监控和调整。人工智能的道德训练包括为其提供无偏见的数据、确保训练过程的多样性,以及定期更新模型以符合不断发展的人类价值观和道德规范。这是技术进步与道德责任之间的微妙平衡。
结论
在 Llama2-7b 等模型中实施 RLHF 的旅程为未来 AI 与我们最高的道德愿望保持一致铺平了道路。这一旅程不仅仅是一项技术努力,也反映了我们致力于创造一个技术尊重和维护人类尊严和价值观的世界。通过采用 TensorFlow 和 OpenAI Gym 等先进工具,并将它们与人类的洞察力和判断力相结合,我们正在创建不仅智能而且明智和道德的 AI 系统。
进一步的学习资源
如果您觉得本文有用,请查看我在 Pluralsight 上关于深度学习和机器学习的课程。Pluralsight 还提供基于视频的学习路径,您可以从中根据自己的技能水平开始学习,无论您是 ML 初学者、从业者还是专家。
此外,如果您有兴趣更具体地研究 RLHF,请查看 Pluralsight 关于 从人类反馈进行强化学习(RLHF) 的专门课程。
附录
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!














